Par où commencer concrètement avec l'IA dans un fonds ?
La question du point de départ avec l’IA dans un fonds est souvent abordée sous le mauvais angle. Le sujet n’est pas de choisir un outil, mais d’identifier où l’IA peut améliorer concrètement l’efficacité opérationnelle, la qualité des données ou la qualité de décision.
Dans la majorité des sociétés de gestion, les premiers gains ne se situent pas sur des usages complexes ou “spectaculaires”. Ils apparaissent plutôt sur des tâches répétitives, consommatrices de temps et à faible valeur ajoutée intellectuelle : consolidation de reportings, préparation de synthèses, recherche d’informations dans des documents, production de comptes-rendus, structuration de données issues de fichiers hétérogènes ou traitement d’emails récurrents.
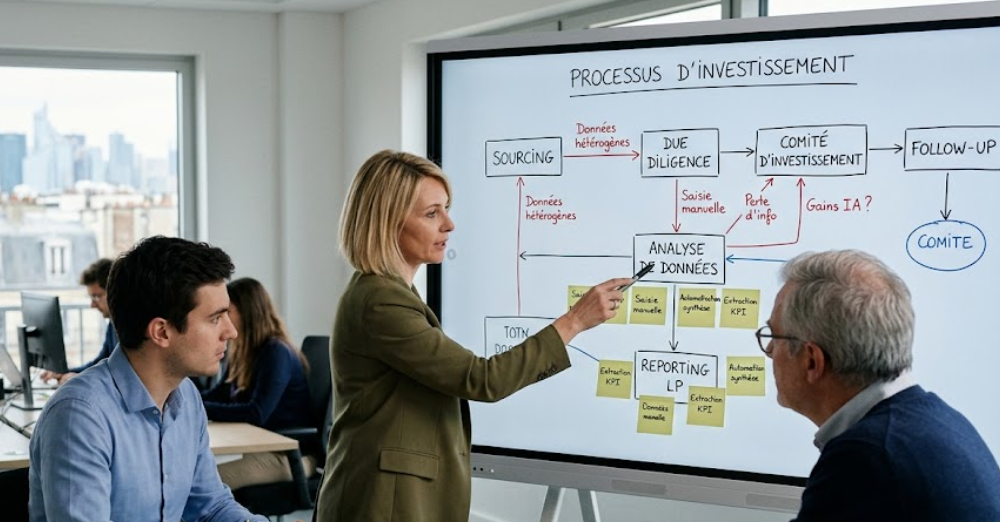
La première étape consiste donc à analyser les processus existants. Il faut comprendre comment les équipes travaillent réellement : où circulent les données, quels outils sont utilisés, où se trouvent les doubles saisies, les retraitements manuels, les pertes d’information ou les dépendances Excel.
Cette phase de cartographie est essentielle, car elle permet d’identifier les zones de friction opérationnelle et les points où l’IA peut apporter un gain immédiat sans modifier profondément les organisations.
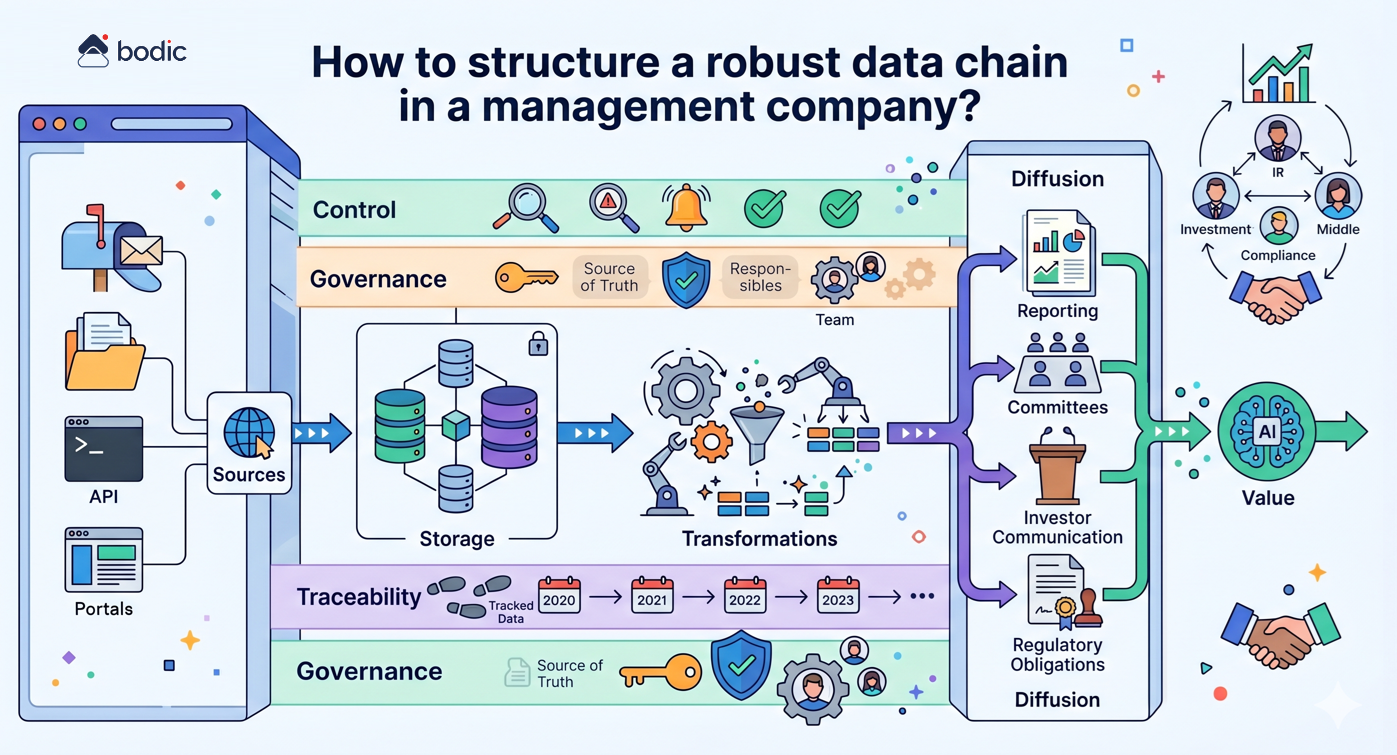
La deuxième étape consiste à structurer un minimum la chaîne de donnée. Même une IA performante produit des résultats faibles si elle repose sur des données incohérentes, dispersées ou non gouvernées. Il n’est pas nécessaire de construire immédiatement une architecture complexe, mais il faut disposer d’une base fiable : données centralisées, définitions communes et règles de validation minimales.
Une fois ce socle posé, il devient possible de lancer quelques cas d’usage ciblés, avec trois caractéristiques : un périmètre limité, une valeur mesurable et un risque opérationnel faible.
Les projets les plus efficaces sont souvent très pragmatiques : automatisation de synthèses de mémos, extraction d’informations depuis une data room, préparation de reporting LP, assistance à la recherche documentaire ou structuration de KPI participations.
L’erreur classique consiste à vouloir déployer une stratégie IA globale avant d’avoir stabilisé les fondamentaux data et opérationnels. À l’inverse, les fonds qui avancent efficacement sont ceux qui construisent progressivement : structuration de la donnée, premiers cas d’usage métiers, montée en compétence des équipes, puis industrialisation.
L’IA doit être pensée comme une couche d’accélération au-dessus d’une organisation déjà maîtrisée. Sans fondations solides, elle amplifie les fragilités existantes. Avec une chaîne de donnée structurée et des usages bien cadrés, elle devient un levier opérationnel extrêmement puissant.
Dans la majorité des sociétés de gestion, les premiers gains ne se situent pas sur des usages complexes ou “spectaculaires”. Ils apparaissent plutôt sur des tâches répétitives, consommatrices de temps et à faible valeur ajoutée intellectuelle : consolidation de reportings, préparation de synthèses, recherche d’informations dans des documents, production de comptes-rendus, structuration de données issues de fichiers hétérogènes ou traitement d’emails récurrents.
La première étape consiste donc à analyser les processus existants. Il faut comprendre comment les équipes travaillent réellement : où circulent les données, quels outils sont utilisés, où se trouvent les doubles saisies, les retraitements manuels, les pertes d’information ou les dépendances Excel.
Cette phase de cartographie est essentielle, car elle permet d’identifier les zones de friction opérationnelle et les points où l’IA peut apporter un gain immédiat sans modifier profondément les organisations.
La deuxième étape consiste à structurer un minimum la chaîne de donnée. Même une IA performante produit des résultats faibles si elle repose sur des données incohérentes, dispersées ou non gouvernées. Il n’est pas nécessaire de construire immédiatement une architecture complexe, mais il faut disposer d’une base fiable : données centralisées, définitions communes et règles de validation minimales.
Une fois ce socle posé, il devient possible de lancer quelques cas d’usage ciblés, avec trois caractéristiques : un périmètre limité, une valeur mesurable et un risque opérationnel faible.
Les projets les plus efficaces sont souvent très pragmatiques : automatisation de synthèses de mémos, extraction d’informations depuis une data room, préparation de reporting LP, assistance à la recherche documentaire ou structuration de KPI participations.
L’erreur classique consiste à vouloir déployer une stratégie IA globale avant d’avoir stabilisé les fondamentaux data et opérationnels. À l’inverse, les fonds qui avancent efficacement sont ceux qui construisent progressivement : structuration de la donnée, premiers cas d’usage métiers, montée en compétence des équipes, puis industrialisation.
L’IA doit être pensée comme une couche d’accélération au-dessus d’une organisation déjà maîtrisée. Sans fondations solides, elle amplifie les fragilités existantes. Avec une chaîne de donnée structurée et des usages bien cadrés, elle devient un levier opérationnel extrêmement puissant.